Attention is all you need学习
基础:NN
NN 通常指 神经网络(Neural Network),是一类用“很多层可学习的线性变换 + 非线性激活”来拟合复杂函数的模型。
过去使用的方法:RNN
循环神经网络(RNN)是一类专门处理序列数据的神经网络 RNN核心思想 在时间步 t: 当前隐藏状态 ht 由 当前输入 xt 和 上一步隐藏状态 ht−1 共同决定 当前输出 yt 由当前隐藏状态 ht 计算得到 本质:信息在时间维度上循环传递,保留历史状态。
自注意力
序列里每个位置 i 的表示,会根据它对序列中所有位置 j 的“相关性”去加权汇聚信息,从而让它能直接“看见”远处的 token。
给定输入向量序列 ,先做三组线性投影:
- (Query) 当前位置“想要什么信息/用什么标准去匹配”
- (Key) 每个位置“我有什么特征可以被匹配(供别人来找我)”
- (Value) 真正要被汇聚走的“内容信息”
然后计算注意力权重与输出(Scaled Dot-Product Attention):
- :每个位置对其它位置的相似度分数(相关性)。
- 除以 :防止维度大时点积过大导致 softmax 过饱和、梯度不稳定。
- softmax:把分数归一化成权重(每行和为 1),表示“我该关注谁”。
多头注意力
同一次注意力不只算一套权重,而是并行算 h 套(h 个“头”),每个头在不同的投影空间里关注不同关系
得到多张A⁽¹⁾,A⁽²⁾,…,A⁽ʰ⁾。比如同一句话里: 一些头更关注局部邻近词(短语结构) 一些头更关注指代/主谓等长距离依赖 一些头可能学到位置/句法边界之类规律
编码器
编码器做什么:把输入序列通过自注意力等层变成一串“上下文化表示”H=[h₁,…,hₙ]。可以理解为:每个输入词都被“结合上下文重新表征”了。
解码器
解码器做什么:按时间步生成输出y₁,y₂,…。每一步先对“已生成的输出前缀”做 masked self-attention(只能看见左边的词,不能偷看未来),再去“看”编码器输出H,最后预测下一个词。
前馈网络(FFN)
在 attention 把“该看谁”处理完之后,再对每个位置的特征做一次更强的非线性加工。 FFN(x) = W2 * activation(W1 * x + b1) + b2 先线性变换一次,过激活函数,再线性变换一次。之前看CNN提到激活函数用于将线性变为非线性
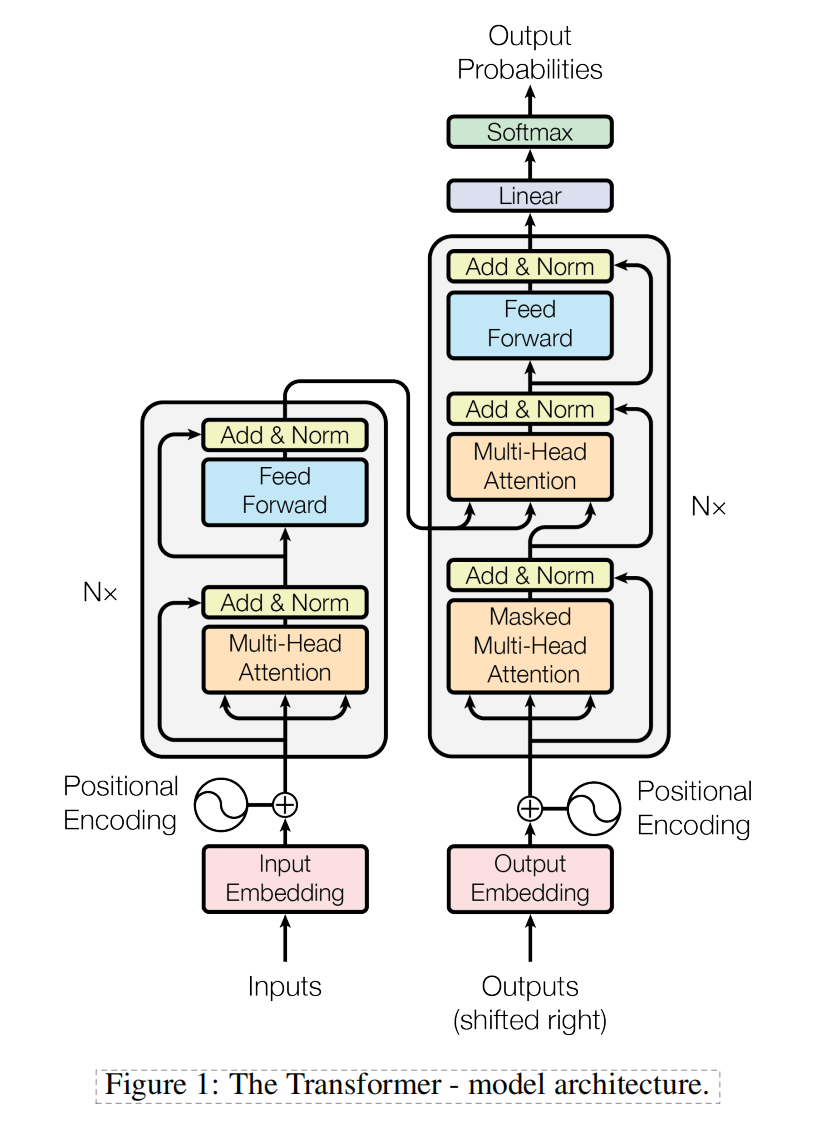
Transformer 整体结构图
- Input Embedding 把词变成向量
- Positional Encoding 给模型加入位置信息
- Multi-Head Attention 用来让一个词关注句子里其他词,捕捉关系
- Feed Forward 是逐位置的前馈网络,进一步做特征变换
- Add & Norm 表示 残差连接 + LayerNorm,作用是让训练更稳定
- Masked Multi-Head Attention。这里的 Masked 表示生成当前词时,只能看见前面已经生成的词,不能偷看后面的正确答案